aggra-guide
Advanced
This wiki walks through the more advanced features of Aggra: features that you don’t need to learn about when creating your first graphs but may want to understand more in-depth as you get more familiar with the framework.
Roles
Property
Every node has a String-based Role property. Its role describe what the node does (i.e. not how it does it or why – simply the what).
The main use case for roles is as a sort of brief, “unique” name-like property for use cases like metricing. “unique” is in quotes, because there’s no enforcement of uniqueness across nodes, only that consumers of the role might want to treat roles as if they were unique (e.g. recording metrics would result in duplicate recordings if role names were the same for different nodes).
Validation
Roles have the concept of validation as represented by the Role.Validator and Role.ValidatingFactory class. This concept is useful for two main usecases:
- Conformity – in targeting specific usecases (e.g. metricing), it might be necessary to make sure the role conforms to certain rules (e.g. what characters it can contain and how long it can be). Role can’t possibly hard-wire every use case consistently inside of itself, so it instead allows users to define validations of their own.
- Uniqueness – if it’s desirable that roles have unique names, then a validating role factory that prevented duplicates from being created might be useful. Now, you couldn’t mandate that node creators use the factory, but it could be a best practice. You can also pair this idea together with a GraphValidator (described more in a section below) to crawl the graph before creation and make sure no duplicates exist. The factory catches duplicates sooner, but the validator can provide more context when failures happen and also provides a strict guarantee that no duplicates are present in the graph (as long as you remember to add it as a graph-level validator when creating the graph).
Closing a GraphCall
As explained in the basics wiki, users create GraphCalls in order to make calls to one or more root nodes. Then, when done, users are supposed to close the GraphCalls. Why and what’s the best way to do that?
Why
When calling a root node through a GraphCall object, users initiate work. It’s a good idea to make sure that work is done before moving onto the next GraphCall. That way users can make sure that work isn’t building up in the background, slowly leaking resources away from the environment (e.g. CPU, threads, etc.). That’s where (weakly) closing the GraphCall comes into play.
(Weak) Closure
When users are done with a GraphCall, they can signal that by calling the weaklyClose method. After calling weaklyClose, you should not make another call to another root node through the GraphCall object (or try to close the GraphCall again). (The word “weak” is there because although the GraphCall object has protections in place to prevent further node calls or closings, that protection is not guaranteed to work 100% of the time.) The weaklyClose method returns a CompletableFuture object which will not complete until all nodes in the GraphCall are complete. In addition, as soon as all root node calls themselves complete, Aggra will cancel whatever nodes remain in progress (because since the root nodes are the only way for you to access results, since they’re complete, whatever node calls are still in progress must not be relevant to the results you’re looking for). Waiting on the CompletableFuture (or chaining actions to happen after it’s complete) allows users to wait until all work associated with that GraphCall object is done (so long as you haven’t initiated work outside of the Aggra framework in background threads yourself, which Aggra would have no idea is there and could not control). The last thing to mention is that the CompletableFuture provides a snapshot of the GraphCall’s FinalState, which contains things like ignored Replies and unhandled exceptions (which you can read about further in the cancellation wiki.
In an ideal world where you could trust nodes 100%, weaklyClose is all you’d need. However, what if one of the nodes goes rogue and hangs forever? The CompletableFuture returned by the weaklyClose call would never complete. If that CompletableFuture is taking up resources itself (e.g. taking up a Thread by calling join or get with no timeout or being responsible for returning an outbound response to an inbound service call), then you’d want some way to limit the damage. One way of doing that is to use a timeout when accessing the CompletableFuture (e.g. using the timeout-variants of join or get), but that will leave it up to you to cancel the GraphCall and even then you’d be left without a snapshot of the GraphCall’s state. That’s where abandon comes into play.
Abandon
At a certain point after waiting for the response from weaklyClose to finish, it may makes sense to cut your losses: accept that nodes may currently be running and may start running again some time in the future, but get a snapshot of what’s already happened and minimize any future damage. That’s what abandon does. When users call abandon, Aggra immediately cancels whatever nodes are already in progress (although how they respond to it is up to them – see the cancellation wiki for details) and returns a snapshot of the GraphCall’s AbandonedState. The AbandonedState contains similar information as the FinalState from weaklyClose, it’s just that there’s no guarantee that it covers everything that will happen with the GraphCall in the future.
So, at what point do you decide to move on from waiting for the response from weaklyClose to finish to calling abandon? A reasonable strategy is to set a timeout that makes sense for whatever you’re doing: if weaklyClose isn’t done by then, move on to abandon. Aggra provides utility methods to help out here.
Utilities
GraphCall has a number of utility methods that help with closing GraphCalls and moving on to abandon them if necessary:
- weaklyCloseOrAbandonOnTimeout – calls weaklyClose, waits for a maximum amount of time for it to finish, and then calls abandon and returns right away if weaklyClose hasn’t finished, yet.
- finalCallAndWeaklyClose – combines a node call with a subsequent call to weaklyClose. It accepts a handler for the resulting FinalState. It returns a CompletableFuture that will complete when weaklyClose does, after which the handler is run. The CompletableFuture returns the value of the node call. This method is most convenient for GraphCalls where there’s only going to be a single call to a root node.
- finalCallAndWeaklyCloseOrAbandonOnTimeout – combines a node call with a subsequent call to weaklyCloseOrAbandonOnTimeout… all done in a similar way as finalCallAndWeaklyClose, what with the handler and returning the resulting Reply in a CompletableFuture that completes when weaklyCloseOrAbandonOnTimeout does.
Recommendations
If you trust your node calls 100%, then you should call weaklyClose and wait forever on the response to finish before moving on to the next GraphCall… but that’s almost never true. There will always be some doubt. So, the best recommendation is to pair a call to weaklyClose with a call to abandon once you’ve waited long enough for the response from weaklyClose to finish. Aggra provides utilities to do exactly that based on a timeout… but also provides the raw methods in case you have some other strategy you want to take (e.g. maybe you want to wait for timeout1 for weaklyClose to finish, then call GraphCalls triggerCancelSignal to start cancellation, and then wait for timeout2 before moving on to abandon). If you do move on to an abandon (or if a utility method does for you, which you can check via isAbandoned accessors on the State object returned or processed by a handler), you should metric and monitor/alarm on it. Calls to abandon should be rare, as they indicate work backing up inside the GraphCall and potentially lost resources forever. You don’t want to allow those to build up over time and bring your program to a halt.
Handling Unreliable Nodes
The previous section on closing a GraphCall gave some tips for how to handle unreliable/rogue nodes relative to closing/abandoning a GraphCall. There are also additional things you can do to avoid getting to that point or at least limiting the blast radius if you know which specific nodes to target.
Make Them Reliable
The best way to deal with unreliable nodes is to make them reliable. Each node has an inherent behavior associated with it which Aggra runs on the calling thread and returns a CompletableFuture. The behavior should both return the CompletableFuture quickly and complete it eventually. If the behavior is quick enough, nodes are allowed to do both on the calling thread itself. Otherwise, nodes can create and return the CompletableFuture on the calling thread right away and then finish the behavior, including the completion of the CompletableFuture, in another thread.
If the behavior takes too long to return the CompletableFuture, it can delay both consumers and unrelated nodes from either continuing or even starting their behaviors. In the worst case, if the node call was made on another thread as a dependency call and doesn’t return a response before GraphCall’s weaklyClose method is called, then Aggra may remain unaware that the call was made at all and not account for it when deciding that the response from weaklyClose should complete. This would leave the user unaware that the dependency call was still in progress in the background. The best way to avoid this delay is to make sure that each node is doing only a reasonable amount of work on the calling thread and is pushing off any heavy work onto a background thread.
If the CompletableFuture returned by the behavior doesn’t complete at all, then consumers will probably never start at all (unless their resilient). In addition, GraphCalls will never be able to complete and, as per the last section, users will be forced to abandon the GraphCall and live with the possibility of compounding or future resource losses. To avoid this possibility, make sure that every code path in the behavior results in the CompletableFuture completing. Exceptions are probably the easiest way that completions can get lost. Here are a couple of highlighting examples:
CompletableFuture<Integer> response = new CompletableFuture<>();
// If doSomething fails, thenRun will *never* run its supplied completing function
CompletableFuture.runAsync(NeverComplete::doSomething).thenRun(() -> response.complete(5));
// If doSomething fails, whenComplete *will* run its supplied completing function
CompletableFuture.runAsync(NeverComplete::doSomething).whenComplete((r, t) -> response.complete(5));
// If doSomething fails, whenComplete will run, but what if doSomethingElse throws
CompletableFuture.runAsync(NeverComplete::doSomething).whenComplete((r, t) -> {
doSomethingElse();
response.complete(5);
});
return response;
Suppose that response is what’s returned from a behavior. Since it’s created as a separate CompletableFuture from where any logic is run, that logic has the responsibility of completing it. (That is, if response were instead created directly by a call to CompletableFuture’s supplyAsync/runAsync, then it would be a different story.) In the first combination of runAsync and thenRun, the response will not be completed if doSomething throws an exception. That’s because most CompletableFuture chaining methods simply reflect the previous stage’s exception. In contract, handle and whenComplete, the latter of which we see in the second example, do. You can read all about exceptional behavior of CompletableFuture’s chaining methods in CompletionStage’s top-level javadoc. In the last example, we see a call to doSomethingElse followed by the completing logic; if doSomethingElse throws an exception, the completing logic will never be run.
As mentioned above, returning CompletableFutures created through supplyAsync/runAsync avoids these problems, because the CompletableFuture framework itself is responsible for completing them. This does, however, introduce another problem: what if the Executor supplied to those methods doesn’t work as expected? Specifically, what if the Executor doesn’t run those commands supplied to it? If this happens, then the CompletableFuture will never complete. The Runnable Decorating Executor project talks about these problems and ways to avoid it. As a quick summary, be careful if you create Executors that decorate their supplied Runnables (or make use of JDK functionality that does the same) to make sure the supplied Runnable is still run, even in the presence of exceptions. Also, avoid using utilities that don’t follow the Executor contract (which guarantees that submitted Runnables will be run sometime in the future), which surprisingly includes some JDK functionality itself… or at least only use them in extreme cases, like shutting down the JVM.
Support Cancellation
If you have potentially long-running computations for a single node, and if it doesn’t make sense to set a timeout internally, one potential option is to support cancellation. The cancellation wiki talks more about the logistics/various options you have. In this case, composite cancellation signals and/or custom cancel actions are probably the most relevant, since both allow a node to query cancellation status and/or take an action in response to cancellation signals. Just remember to set up your graph correctly so that the cancellation signal is delivered as expected (and make sure to unit test your graphs to make sure that structure holds up over time). The nice thing about this option vs. the remaining options is that you still have control over how the node behaves, but if you don’t, then there are still other options.
Use TimeLimitNodes
TimeLimitNodes, as described in the common types wiki tries to mitigate the effects of the two problems mentioned so far: taking too long to return a response and taking too long to complete the returned response.
First, it offers the ability to call a dependency node on a separate thread from an Executor rather than on the caller thread. This negates the dependency’s ability to delay or block the caller thread by taking too long to return a response (at the cost of needing to jump to another thread just to make the call). In addition, TimeLimitNodes does this in such a way that Aggra is aware that the dependency call was made, even if in the worst case, the dependency call never returns. This is a subtle feature that keeps users aware of a still-running dependency call when they call GraphCall’s weaklyClose method. Second, it offers the ability to set a timeout on how long to wait for the dependency node’s response to complete. This mitigates the dependency’s ability to block consumers waiting for the response (at the cost of consumers receiving an exceptional response on timeout). Neither ability addresses the root problem, though: the dependency node, once called, will continue to “do what it’s doing” once called.
One strategy that you could pair with TimeLimitNodes to further limit damage would be creating a dedicated memory and making the time-limit node the entry point. Let’s walk through an example to see what I mean.
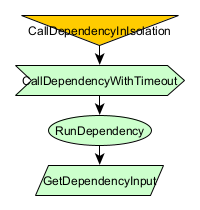
public class DamageLimit {
private static class MainMemory extends Memory<Integer> {
private MainMemory(MemoryScope scope) {
super(scope, CompletableFuture.completedFuture(null), Set.of(), () -> new ConcurrentHashMapStorage());
}
}
private static class DependencyMemory extends Memory<Integer> {
private DependencyMemory(MemoryScope scope, CompletionStage<Integer> input) {
super(scope, input, Set.of(), () -> new ConcurrentHashMapStorage());
}
}
public static void main(String args[]) {
Node<DependencyMemory, Integer> getDependencyInput = Node.inputBuilder(DependencyMemory.class)
.role(Role.of("GetDependencyInput"))
.build();
Node<DependencyMemory, Integer> runDependency = FunctionNodes
.synchronous(Role.of("RunDependency"), DependencyMemory.class)
.apply(num -> num + 100, getDependencyInput);
Node<DependencyMemory, Integer> callDependencyWithTimeout = TimeLimitNodes
.startNode(Role.of("CallDependencyWithTimeout"), DependencyMemory.class)
.callerThreadExecutor()
.timeout(10, TimeUnit.MILLISECONDS)
.timeLimitedCall(runDependency);
Node<MainMemory, Integer> callDependencyInIsolation = MemoryTripNodes
.startNode(Role.of("CallDependencyInIsolation"), MainMemory.class)
.createMemoryNoInputAndCall(
(scope, parent) -> new DependencyMemory(scope, CompletableFuture.completedFuture(4)),
callDependencyWithTimeout);
System.out.println(callDependencyInIsolation);
}
}
Here, we set a potentially rogue dependency: RunDependency. It’s got its own dedicated memory: DependencyMemory. In front of it, but still inside the DependencyMemory is a time-limit node: CallDependencyWithTimeout. Outside of that, in the main Memory, is the node responsible for creating the DependencyMemory and calling the time-limit node within it: CallDependencyInIsolation.
What benefits does this pattern offer? Well, if CallDependencyWithTimeout times-out, that will trigger DependencyMemory’s MemoryScope cancellation signal (see the cancellation wiki for more details on what this means). Once triggered, any newly-called node in the DependencyMemory (or any memory created from a node inside of it) will be cancelled immediate, without the node’s inherent behavior being run. Although not really relevant in the simplified example above, this pattern would limit the damage that the dependency node could do by causing any newly-called nodes within its memory shadow to fail immediately.
There are still some downsides. First, the dependency node is still free to call new nodes in its ancestor memories. Users can limit damage from this by preventing access to the ancestors (as DependencyMemory doesn’t provide access to MainMemory in the example above). If the dependency node needs nodes from the ancestor, CallDependencyInIsolation (in our example above) could call those nodes for it and provide the results as input. The downside of that is that CallDependencyInIsolation might not know the full conditions of when the call should be made and that waiting for the input to be ready might delay work that the dependency node could have done in parallel. So, it’s a tradeoff.
Second, TimeLimitNodes, when using a timeout, have a DependencyLifetime of GRAPH. As explain in the section on node phases, there are costs associated with this DependencyLifetime. Re-establishing the NODE_FOR_ALL DependencyLifetime quickly probably isn’t an option here, as that may defeat the point of the time-limit node in the first place. However, you could expose the time-limit node to as few consumers as possible to limit that cost.
Abandon Background Tasks
The previous approach based on TimeLimitNodes abandons node calls after a time, but then you have to pay for that later by waiting for GraphCall’s weaklyClose and then potentially abandoning that GraphCall itself. In contrast, the idea here with this current approach is to abandon the background tasks that would normally complete the response from the node call instead.
To be up-front, this is an equally bad option! Aggra intentionally guides you to wait on the response from weaklyClose to make sure that all background work associated with a GraphCall is complete by the time you accept more work. This makes sure that your program remains stable and doesn’t drain resources over time. There are, however, some benefits to abandoning a task instead. Plus, if you have to end up abandoning the GraphCall at some point anyway, then this approach is essentially doing the same type of thing, just at a different level.
Let’s take a look at an example.
public class AbandonTask {
private static class TestMemory extends Memory<Integer> {
private TestMemory(MemoryScope scope) {
super(scope, CompletableFuture.completedFuture(null), Set.of(), () -> new ConcurrentHashMapStorage());
}
}
public static void main(String args[]) {
ExecutorService executor = Executors.newCachedThreadPool();
Node<TestMemory, Void> abandonTask = CompletionFunctionNodes
.threadLingering(Role.of("AbandonTask"), TestMemory.class)
.get(() -> {
return CompletableFuture.runAsync(AbandonTask::doTask, executor).orTimeout(1, TimeUnit.SECONDS);
});
System.out.println(abandonTask);
}
private static void doTask() {
// Something important here
}
}
In the above example, the AbandonTask node starts doTask running on an executor in the background, but will then abandon it after 1 second if it’s not yet done. At that point, Aggra sees the completed response and continues on, blissfully unaware that the doTask method is still running in the background.
On the plus side, the GraphCall remains uncomplicated: AbandonTask can keep the default DependencyLifetime of NODE_FOR_DIRECT while the consumers also don’t have to timeout themselves. On the negative side, doTask keeps running in the background for who knows how long, occupying a thread in a thread pool somewhere doing who knows what. It’s the nature of that background task and the work it’s doing that helps you decide if this tradeoff is worth it. E.g. maybe you’re not taking up a background thread at all; maybe you’re making a service call with a push-based future paradigm, not really taking up any significant resources that won’t take care of themselves. In that situations, maybe it makes sense to abandon the task. On the other hand, if you’re running a complex calculation on a background thread that you don’t know when it will finish, then abandoning it will probably build up background tasks, slowly consuming the program’s resources until it crashes.
As with abandoning a GraphCall, you should also follow the same recommendations when deciding to abandon a task. Make sure you’re recording metrics and monitoring/alarming based on it. Calls to abandon should be rare, as they indicate work backing up inside the GraphCall and potentially lost resources forever. You don’t want to allow those to build up over time and bring your program to a halt.
Exceptions
When a user calls a graph node, the node runs its inherent behavior, and then returns a Reply object to access results. Reply is a CompletableFuture-like class but one of the ways it differs is how it represents exceptional responses.
Internal Representation
The internal representation of any exceptional Reply object is a CompletionException wrapping a CallException wrapping an encountered exception. Let’s walk through that statement:
- Internal representation – the internal representation is how the Reply object stores its exception. This is the exception object that users will see when they chain computations on the end (e.g. Reply#whenComplete). This is also the exception that users will see when they call any join-like methods on the Reply. On the other hand, users will see a slightly different exception when they call any get-like methods on the Reply. get-like methods will get rid of the top-level CompletionException and replace it with an ExecutionException. This is normal for a CompletableFuture-like object.
- CompletionException – a CompletableFuture-related, unchecked join-equivalent of the checked ExecutionException thrown by Future#get. This is a part of the internal representation to make sure it maintains the same form regardless of how it was created (more on that later).
- CallException – an Aggra-specific exception that allows the addition of caller information as an exception propagates up through a graph. This helps provide the graph-equivalent of a call stack for useful debugging information (that CompletableFuture, itself, lacks).
- Encountered exception – the encountered exception is the exception encountered/seen as a part of completing the Reply. This could be the exception thrown by or the exceptional response returned by the Node’s behavior. This could be an exception that prevented the behavior from running at all. Either way, this is the Aggra-untouched exception “experienced” by the node. If users want to vary behavior based on what exception a dependency returns, this encountered exception is usually what they want to interact with… but not directly.
Encountered Exception
As mentioned above, the encountered exception is the exception “experienced” by the node. However, there are nuances here. The behavior inherent to every Node is closely related to raw CompletableFutures. We saw above that Reply returns a consistent internal representation, but the same is not true of CompletableFutures. Take the following code example:
public class CompletableFutureExceptions {
public static void main(String args[]) {
IllegalArgumentException exception = new IllegalArgumentException();
System.out.println("Constructed");
CompletableFuture<Integer> constructed = CompletableFuture.failedFuture(exception);
reportAccessPatterns(constructed);
System.out.println("\nThrown");
CompletableFuture<Integer> thrown = CompletableFuture.supplyAsync(() -> {
throw exception;
});
reportAccessPatterns(thrown);
}
private static void reportAccessPatterns(CompletableFuture<?> future) {
future.whenComplete((r, t) -> System.out.println("Chained: " + causes(t)));
Try.callCatchRuntime(future::join).getFailure().ifPresent(t -> System.out.println("Joined: " + causes(t)));
Try.callCatchException(future::get).getFailure().ifPresent(t -> System.out.println("Gotten: " + causes(t)));
}
private static List<Class<? extends Throwable>> causes(Throwable t) {
List<Class<? extends Throwable>> causes = new ArrayList<>();
Throwable current = t;
do {
causes.add(current.getClass());
current = current.getCause();
} while (current != null);
return causes;
}
}
This example produces the following output:
Constructed
Chained: [class java.lang.IllegalArgumentException]
Joined: [class java.util.concurrent.CompletionException, class java.lang.IllegalArgumentException]
Gotten: [class java.util.concurrent.ExecutionException, class java.lang.IllegalArgumentException]
Thrown
Chained: [class java.util.concurrent.CompletionException, class java.lang.IllegalArgumentException]
Joined: [class java.util.concurrent.CompletionException, class java.lang.IllegalArgumentException]
Gotten: [class java.util.concurrent.ExecutionException, class java.lang.IllegalArgumentException]
We can see a couple of things here:
- We see the same CompletionException-unwrapping and ExecutionException wrapping when calling get-like methods that Reply has.
- Unlike with Reply, we see that the CompletableFuture’s internal representation changes based on how it “experiences” the exception. If the CompletableFuture is set with the exception directly, that’s the internal representation; if the exception is thrown, the internal representation is the exception wrapped in a CompletionException. This difference matters, because as mentioned above, functionality chained on the end of a CompletableFuture depends on this internal representation.
This example is far-reaching and shows how, depending on how a CompletableFuture is manipulated, that may change its internal representation. Since the Node’s behavior is CompletableFuture-based and since the “encountered exception” is (in a large percentage of cases) the behavior’s response, then the encountered exception can change form unexpectedly. On the bright side, the changes happen in predictable ways. This is why Reply provides a number of accessors to help the user retrieve consistent results.
(Note: you may ask why Aggra doesn’t just remove the extra CompletionExceptions added by CompletableFuture to make the encountered exception consistent. There are a couple of reasons. First, Aggra doesn’t know if the user threw a CompletionException directly or CompletableFuture added one extraneously. Agga doesn’t want to remove any potentially useful debugging information present in the first case. Second, CompletableFuture’s behavior pervades every method such that it’s tedious to remove them and impossible to force users to do the same.)
Accessors
The Reply object provides the following accessors for exceptional information. They all return empty Optionals if the Reply is either incomplete or non-exception. However, if the Reply is complete and exceptional, then
- getExceptionNow – returns the Reply’s internal representation exception (a CompletionException).
- getCallExceptionNow – returns the Reply’s CallException
- getEncounteredExceptionNow – return the Reply’s encountered exception (again, you usually don’t want to call this directly)
- getFirstNonContainerExceptionNow – returns the first non-CompletionException, non-ExecutionException, and non-CallException in the internal representation’s exception chain. In practice, this means the “encountered exception”, unless CompletableFuture has wrapped it extraneously in an extra CompletionException, in which case that will be skipped. This, this is the method that you want to call if you want to access the exception thrown by a dependency node’s behavior.
Propagation
When a dependency node returns an exceptional response, it’s likely that the consumer node will access that response and end up throwing the same exception. When this happens, the exception is considered to have “propagated up the graph”. Aggra offers a couple of different options to the user in this case, depending on the consumer Node’s ExceptionStrategy (which is settable by the user):
- Suppress dependency failures (default) – the default behavior is to “suppress dependency failures”. What this means is that if every dependency node’s Reply throws the same Reply exception, then Aggra adds the consumer node to the Reply exception’s CallException and then returns that same Reply exception as its response. If any one of the dependency node exceptions differs, then a new Reply exception is made, all dependency exceptions are added to it as suppressed exceptions, and the new Reply exception is returned as the consumer node’s response.
- Discard dependency failures – in this case, the other dependency failures don’t matter: only the propagated failure matters. Aggra adds the consumer node as a caller to the propagated exception’s CallExeption, and then returns the propagated exception as the consumer node’s response. Be careful using this, as it loses some dependency failure information (which is why it’s not the default).
Unhandled Exceptions
There are a number of exceptions during the process of a GraphCall that Aggra suppresses. Aggra does this because the exceptions are considered secondary to returning a response for a Reply. Agga makes these unhandled exceptions available to user for processing as a part of the GraphCall’s FinalState (or AbandonedState). This is part of Aggra’s commitment to allow the user to process every exception thrown during a GraphCall, whether thrown by user-provided code or Aggra itself. See GraphCall.FinalState#getUnhandledExceptions for more information.
Node Phases
Each node run has 3 different phases:
- Priming phase – during this first phase, all of a node’s PRIMED dependencies are primed automatically by Aggra. Only after all of the dependency calls are finished does the next phase begin (depending on the PrimingFailureStrategy).
- Behavior phase – during this phase, nodes perform their inherent behavior, which includes calling other dependencies. If the behavior calls a primed dependency, then the behavior can be sure that, because of memoization, the call will already be complete, and the behavior can immediately access the response without fear of blocking the current thread. Otherwise, for UNPRIMED dependencies, users have to take into account that it may take arbitrarily long for the call to complete and plan accordingly so as not to block the calling thread (e.g. by executing the logic in a different thread and using CompletableFuture’s chainable methods to execute logic after that). The complexity of “plan accordingly” shows the use of declaring dependencies to be primed: the behavior can simply call and access it. The downside is that primed dependencies are always run.
- Waiting phase – during this last phase, the consumer node waits around (non-blockingly) until its dependencies complete (depending on the DependencyLifetime).
Dependency PrimingModes
Nodes declare their dependencies on other nodes. When they do that, consumers declare the relationship’s priming mode. There are two types:
- PRIMED – the dependency will be called/primed automatically during the consuming node’s priming phase.
- UNPRIMED – the dependency will not be called/primed during the consuming node’s priming phase. It’s solely the consuming node’s behavior’s responsibility to call the dependency node explicitly.
Note: in order to enforce DependencyLifetime, Aggra tracks each node’s dependency calls. This is extremely easy to do with primed dependencies given their predictability. Unprimed dependencies, though, take more effort (specifically synchronization). So, if you have a choice, choose primed dependencies over unprimed (although sometimes this can’t be avoided (e.g. conditional calls or calls to other memories)).
PrimingFailureStrategy
Each node can declare how it responds to failures returned by primed dependencies. There are two options:
- WAIT_FOR_ALL_CONTINUE (default) – the default strategy is to wait around for all of primed dependencies to complete anyway and then continue on with the behavior phase. This is the default strategy because Aggra can’t possibly know whether a dependency failure is expected or recoverable.
- FAIL_FAST_STOP – in this strategy, the priming phase completes as soon as the first returned failure is detected. The behavior phase is skipped completely, and the failure is taken to be the consuming node’s response. This strategy is useful if you know that the consuming node is going to fail if any primed dependency fails, and so there’s no need to execute that behavior or wait around for other primed dependencies to finish first.
DependencyLifetime
Nodes declare how long their dependencies lifetimes last relative to the consuming node. These lifetimes affect what dependencies a consuming node waits around for in the waiting phase. There are three options:
- NODE_FOR_ALL – all of a node’s dependencies (both direct and transitive) must finish before the consuming node call is allowed to finish.
- NODE_FOR_DIRECT (default) – only the node’s direct dependencies must finish before the consuming node call is allowed to finish. The transitive nodes can finish at whatever time after that (up to the graph level). This is the default strategy because if every node in the graph has NODE_FOR_DIRECT, then every node effectively has NODE_FOR_ALL (since every node waits for their direct dependencies which wait for their direct dependencies, etc.), which is the most conservative strategy. At the same time, if any node wants its dependencies’ lifetimes to escape to the next level (i.e. GRAPH), it can control that without affecting how other NODE_FOR_DIRECT consumers act, which allows for modularity.
- GRAPH – all of the consuming node’s dependencies can finish whenever, up to the limit of the overall graph call. This lifetime is useful in case the consuming node can finish computing its response while one of its dependencies is still running: waiting for that dependency to finish would only delay the consuming node’s consumers from running. Words of caution:
- Be careful when using this lifetime to make sure that no consumers of the consuming node (either direct or transitive) depend on any of the consuming node’s dependencies being done by the time those consumers run.
- It takes Aggra more effort to track this lifetime. In addition, this cost trickles up the graph consumer-by-consumer until the NODE_FOR_ALL lifetime is re-established. Specifically, Aggra tracks NODE_FOR_ALL (or effectively NODE_FOR_ALL) nodes for free. Changing that costs (essentially) an extra CompletableFuture and an extra call to CompletableFuture#allOf for each node that doesn’t have this (effective) lifetime.
Observers
Each graph call accepts an Observer. The Observer observes different aspects of each node call made during that graph call:
- First call – the first, uncached full call made to a node
- Behavior – the behavior phase of the first call
- Custom cancel action – the execution of any custom cancel action
- Every call – all calls to a node, both cached and uncached (due to memoization)
Some example, hypothetical use cases might be recording latency metrics, recording timeline metrics (to figure out if some piece of logic is blocking another or whether custom cancel actions are running soon enough), to create a graph visualization of all node calls made during a specific graph call, or to figure out which node isn’t finishing for stalled graph calls.
Observers are formed in two parts: a piece of logic that runs before one of these “aspects” and a piece of logic that runs after. The latter piece is produced by the former, in order to pass along any necessary state. Observers have a robust framework to declare generic observers and use them for every aspect, or to create composite or fault-tolerant observers, or some combination of them all.
Below is a naive example creating an observer that records the latency for every first call and its behavior.
public class LatencyObserver {
public static void main(String args[]) {
ConcurrentLinkedQueue<LatencyRecord> latencyRecords = new ConcurrentLinkedQueue<>();
ObserverBeforeStart<Object> latencyRecordingObserver = latencyRecordingObserver(latencyRecords);
Observer observer = Observer.builder()
.observerBeforeFirstCall(latencyRecordingObserver)
.observerBeforeBehavior(latencyRecordingObserver)
.build();
System.out.println(observer);
// Perform a graph call here and wait for it to be done
// Process the latency records here
}
private static ObserverBeforeStart<Object> latencyRecordingObserver(
ConcurrentLinkedQueue<LatencyRecord> latencyRecords) {
return (type, caller, node, memory) -> {
long start = System.nanoTime();
return (result, throwable) -> {
Duration duration = Duration.ofNanos(System.nanoTime() - start);
LatencyRecord record = new LatencyRecord(type, caller, node, duration);
latencyRecords.add(record);
};
};
}
public static class LatencyRecord {
private final ObservationType type;
private final Caller caller;
private final Node<?, ?> node;
private final Duration duration;
public LatencyRecord(ObservationType type, Caller caller, Node<?, ?> node, Duration duration) {
this.type = type;
this.caller = caller;
this.node = node;
this.duration = duration;
}
public ObservationType getType() {
return type;
}
public Caller getCaller() {
return caller;
}
public Node<?, ?> getNode() {
return node;
}
public Duration getDuration() {
return duration;
}
}
}
Graph Validators
Aggra aims to prevent invalid Graphs as quickly as possible. For example, you can’t depend on a Node unless you’ve already created it, which eliminates dependency cycles… or if you set the PrimingFailureStrategy with an invalid DependencyLifetime, an exception is thrown right away, before the Node can even be created. Those types of validations only require knowledge of a Node’s dependencies or the direct data it’s based on. There are, however, some types of validations that require consumer information as well, which can only be known once you have the entire graph structure in place. For these types of validations, Aggra has a GraphValidator framework.
GraphValidator
GraphValidator is an interface that accepts a GraphCandidate and validates it, doing nothing if the candidate is valid and throwing an exception if it’s not. A GraphCandidate is a pre-Graph structure that can be transformed into a fully-fledged Graph once the candidate has been validated.
There are two types of GraphValidators: graph-level and node-specific. Users can specify graph-level validators when they try to create a Graph (either from root nodes or a GraphCandidate directly). Node-specific validators are properties set on each node individually: they represent restrictions on what kinds of graphs a node is allowed to be a part of.
Here’s how the validation process works. Users try to create graphs. Aggra visits each node in the candidate and collects together all of the node-specific validators. Aggra them combines those validators with the graph-level validators and runs all of them against the candidate. If all validators pass, Aggra transforms the candidate into a Graph.
A good way to understand this concepts is to look at three validators present in the Aggra framework itself (whose code you can examine freely): GraphValidators#ancestorMemoryRelationshipsDontCycle, GraphValidators#consumerEnvelopsDependency, and TryWithResource#validateResourceConsumedByTryWithResource.
GraphValidators#ancestorMemoryRelationshipsDontCycle
A graph is composed of a set of nodes. Each node is associated with a memory. Nodes are allowed to access nodes in ancestor memories. Because memories should form a hierarchical relationship, that means there should be no cycles in ancestor-memory accesses (e.g. if Memory1 accesses ancestor Memory2, then it wouldn’t make sense for Memory2 to access Memory1 as an ancestor as well).
ancestorMemoryRelationshipsDontCycle validates that this relationship holds. ancestorMemoryRelationshipsDontCycle is a graph-level validator that Aggra adds automatically to every candidate check. It would be ideal if it were impossible for users to create a invalid ancestor-memory accessing graph candidate in the first place, but in order to allow flexible Memory hierarchies (see the basics wiki for more information), it is possible. That’s why this extra validation step is necessary here.
ancestorMemoryRelationshipsDontCycle does its job by transforming a graph of nodes into a graph of ancestor-memory-accesses. E.g. If Node<Memory1, Integer> node1 accesses Node<Memory2, Boolean> node2 as an ancestor then that’s a graph of “node1 -> node2” or replaced with memory, an ancestor-memory-accesses graph “Memory1 -> Memory2”. ancestorMemoryRelationshipsDontCycle then looks for cycles in this ancestor-memory-accesses graph and throws an exception if it finds one.
GraphValidators#consumerEnvelopsDependency
TryWithResourceNodes create nodes that create a resource via a resource node, calls another “output node” that supposedly accesses that resource, and then close the resource once the output node (and its transient dependencies) are done. Because nodes only know about their dependencies and not their consumers, though, it’s impossible for TryWithResourceNodes to check at node creation time that only the output node consumes the resource node. It could be disastrous if other nodes that TryWithResourceNodes doesn’t know about were consuming the resource node as well, because then the try-with-resource node would close the resource at an arbitrary point relative to those consumers’ lifecycles. That’s where consumerEnvelopsDependency comes into play.
consumerEnvelopsDependency creates a validator that makes sure a consumer node envelopes a dependency node. What this means is that every consumer of the dependency must itself be consumed by the consumer node as well (hence the concept of “envelopment”). If that’s not true, the validator throws an exception.
TryWithResourceNodes makes use of this validator by adding one at the node-specific level to the try-with-resource-node that validates that it “envelops” the resource node. Since the try-with-resource node only depends on the resource node and the output node, if the try-with-resource node envelops the resource node, then that means no other consumer besides the output node is consuming the resource node as well.
TryWithResource#validateResourceConsumedByTryWithResource
TryWithResourceNodes tries to protect the resource created by a resource node. What happens if somebody does a refactor, though, and forgets to consume the same resource node with a TryWithResourceNodes? That could be disastrous, as the resource would remain open even after the GraphCall finished. TryWithResourceNodes protects against this possibility by making sure that the resource node has a validateResourceConsumedByTryWithResource node-specific validator as a property. This may seem silly, since in order to create a try-with-resource node, you obviously need it to consume a resource node. The idea is that by mandating that the resource node initially has this check in place as an inherent property of its node, that protects against future changes made outside of that resource node.
Type-Specific Logic
Each node defines a type property. We’ll go into that in more detail below when discussing custom nodes, but the basic idea is that a type is a high-level classification describing how the node does what it does. E.g. FunctionNodes creates nodes of type SYNCHRONOUS_FUNCTION_TYPE when they run a function synchronously.
Now, node behavior should not contain conditional logic based on the type of Node. That is, the behavior should not have any branches that say “if node is type 1, then do X”. There’s just no reason to do that: simply create the right type of node in the first place and leave its logic free from such conditions. There are, however, other use cases where checking type makes sense. The best example is inspecting the graph structure and deciding how to describe it. To help in these cases, Aggra has the concept of a ByTypeVisitor.
ByTypeVisitors run arbitrary functions based on node type. Visitors accept a Node and produce a result. Users create visitors by specifying a Map of Type to the Function that should be run for nodes of that type. Additionally, users must specify a default function to run whenever the visitor encounters a node with a type that’s not contained within that map. So, when a user submits a node to a visitor, the visitor looks up the function to run based on the type of the node, falling back on the default, and then runs that function and returns the result.
Here’s a simple example:
public class TypeVisitation {
private static class TestMemory extends Memory<Integer> {
private TestMemory(MemoryScope scope) {
super(scope, CompletableFuture.completedFuture(null), Set.of(), () -> new ConcurrentHashMapStorage());
}
}
public static void main(String args[]) {
Node<TestMemory, Integer> unknownTypeNode = Node.communalBuilder(TestMemory.class)
.type(Type.generic("unknown"))
.role(Role.of("BeUnknown"))
.build(device -> CompletableFuture.completedFuture(13));
Node<TestMemory, Integer> functionTypeNode = FunctionNodes
.synchronous(Role.of("BeFunctional"), TestMemory.class)
.getValue(4);
Graph<TestMemory> graph = Graph.fromRoots(Role.of("BeGraph"), Set.of(unknownTypeNode, functionTypeNode));
ByTypeVisitor<String> shapeCalculator = yedShapeCalculator();
graph.getAllNodes()
.stream()
.map(node -> node.getRole() + ": " + shapeCalculator.visit(node))
.forEach(string -> System.out.println(string));
}
private static ByTypeVisitor<String> yedShapeCalculator() {
Map<Type, Function<Node<?, ?>, String>> typeToFunction = new HashMap<>();
typeToFunction.put(CaptureResponseNodes.CAPTURE_RESPONSE_TYPE, node -> "trapezoid");
typeToFunction.put(CompletionFunctionNodes.JUMPING_COMPLETION_FUNCTION_TYPE, node -> "ellipse");
typeToFunction.put(CompletionFunctionNodes.LINGERING_COMPLETION_FUNCTION_TYPE, node -> "ellipse");
typeToFunction.put(ConditionNodes.CONDITION_TYPE, node -> "diamond");
typeToFunction.put(IterationNodes.ITERATION_TYPE, node -> "octagon");
typeToFunction.put(FunctionNodes.SYNCHRONOUS_FUNCTION_TYPE, node -> "ellipse");
typeToFunction.put(FunctionNodes.ASYNCHRONOUS_FUNCTION_TYPE, node -> "ellipse");
typeToFunction.put(MemoryTripNodes.ANCESTOR_ACCESSOR_MEMORY_TRIP_TYPE, node -> "up-arrow");
typeToFunction.put(MemoryTripNodes.CREATE_MEMORY_TRIP_TYPE, node -> "down-arrow");
typeToFunction.put(TimeLimitNodes.TIME_LIMIT_TYPE, node -> "fat-right-arrow");
typeToFunction.put(TryWithResourceNodes.TRY_WITH_RESOURCE_TYPE, node -> "rectangle");
typeToFunction.put(Node.InputBuilder.INPUT_TYPE, node -> "right-skewed-parallelogram");
Function<Node<?, ?>, String> defaultVisitor = node -> "8-pointed-star";
return ByTypeVisitor.ofVisitors(typeToFunction, defaultVisitor);
}
}
The above example imagines creating a ByTypeVisitor that specifies the yed shape that should be drawn for each one of the pre-defined node types in Aggra. As a test, the example creates a two-node graph: one node of an unknown type (unknown to the visitor) and one node of a function type. The example then iterates over all nodes in the graph and prints out each node’s role and its yed shape. The resulting output demonstrates the basic idea:
BeUnknown: 8-pointed-star
BeFunctional: ellipse
Custom Node Types
Aggra provides plenty of pre-defined, common node types. Those should suite the majority of use cases, but they can’t cover everything. So, what’s required to create a new type of node?
Type
Each node requires a Type property, which is a string-based description of how the node does what it does. Common node types automatically set the type, but users must decide how to set it for custom nodes. There are two options:
- Generic – the Type class defines a
Type#generic methodthat creates an instance of a generic type (which is a subclass of Type). Generic types compare equal to one another based on their internal string representation (e.g.Type.generic("my-type")compares equal toType.generic("my-type")but notType.generic("my-other-type")). Generic types are for when you don’t really care if two nodes in a graph do things in different ways but accidentally use the same type name. This would be the case, for example, if you didn’t want to run any type-specific logic against a node or identify with certainty how a given node works. - Custom – users can create their own custom Type subclasses. By default, different custom instances don’t compare equal, even if they’re of the same Type subclass. All common nodes in Aggra use this strategy. Those common nodes define a custom, private Type-subclass; they create a single instance of it; and they set that instance on every node they create. This, by itself, could help the nodes ensure proper identification… except that those nodes also expose the common instance they use in order to allow for type-specific logic (as described in the last section). That’s where TypeInstance comes into play.
TypeInstance
Each node requires a TypeInstance property, which describes information about a node instance. This metaphor summarizes the intention: as “class” is to “instance”, “Type” is to “TypeInstance”.
There are two purposes to TypeInstance:
- Ensure identification – as mentioned in the previous section, common nodes expose the single Type object. As a result, anybody could use that same object and set it on their node, which would cause it to be misidentified as being of that type. To prevent against this possibility, Type has a
Type#isCompatibleWithTypeInstancemethod that checks whether the Type is compatible with a given TypeInstance. Whenever TypeInstance is set on a node, it runs this check. Generic types do no validation at all in their implementation. Custom nodes can define validation logic of their own. For example, common nodes create a private TypeInstance subclass and set that on nodes they create. Meanwhile, the common node Types implement their compatibility-check method to make sure that their custom types always require this custom type instance. - Carry extra, accessible instance information – node only has a common set of properties that it exposes for all possible node types. Furthermore, there is only one Node class: users can’t create subclasses to define and expose new properties. Sometimes, though, it’s convenient to define and be able to access extra properties on node instances. For example, to implement its graph validator that checks whether a resource node is consumed by at least one try-with-resource node, TryWithResourceNodes defines a “resourceNode” accessor on its TypeInstance subclass. Its graph validator uses this accessor to identify the resource node that the try-with-resource node refers to (among its other dependencies as well).
Dome node types benefit from TypeInstance (e.g. common nodes), but others don’t care (e.g. generic types). To prevent the latter use cases from having to deal with the concept of TypeInstance at all, TypeInstance defines a default value TypeInstance#defaultValue. Node sets this value by default on each Node instance. Node types that do care about TypeInstance can override this value, while those that don’t care aren’t even presented with it.
Behavior
Every node has a custom behavior (or behavior-like) property, which defines the logic to run when the node is called. Here’s the basic Behavior interface:
public interface Behavior<M extends Memory<?>, T> {
CompletionStage<T> run(DependencyCallingDevice<M> device);
}
When Aggra runs a node’s behavior, it passes a dependency-calling device to it. This device is what allows users to call the node’s dependencies. At the end of the run method, the behavior returns a future-like CompletionStage object. Like a future, this response object can already be complete or it can complete in the future. The response’s completion tells Aggra when the behavior is done, allowing Aggra to initiate completion of the overall Node call as well (i.e. in the terminology of the “Node Phases” section, the response’s completion marks the move from the behavior phase to the waiting phase).
If you’re implementing your own behavior, you should thoroughly read the javadoc for the Behavior interface. You have a lot of important responsibilities to meet. Here’s a quick, non-authoritative summary:
- Return quickly – the run method should return “quickly”. Delays will cascade to other nodes as well. If you need to do a lot of/long work, then inside of run, you should start the work on another thread and then return the response immediately; the work on the other thread, when its done, should complete the response that you returned. There’s a balancing act here: switching to another thread itself costs something and so may delay this node from finishing… but doing the work inside the run method itself will delay other nodes. That’s why “quickly” is in quotes: although in some cases it will be obvious, in general, it’s a balancing act and not precisely defined.
- Make sure the response completes in a timely manner – although, as per the last point, you may push off long work to another thread, so still need to make sure that work completes the response in a timely manner. Until the response completes, Aggra won’t be able to continue running consumers of the node. This delay may propagate up the entire graph and put the user in the uncomfortable position of deciding whether to continue waiting for a GraphCall to complete or just abandon it (and live with the consequences). See the previous discussion in this wiki to understand that decision better.
- Do no work after response completion – if you do run work on another thread, as soon as the work completes the response, you should stop the work as soon as possible. (Another way of saying this: minimize the work you do after completing the response.) The response completion is a signal to Aggra to continue its job: it knows nothing about any work you do after that and will not account for it. Doing substantive work after completing the response will take up resources… unaccounted-for resources that may build up across GraphCalls and slowly degrade the program.
- Exceptions from run are okay – it’s okay to throw an exception from the
runmethod itself. Aggra interprets this as a failed response and proceeds accordingly. However, you should still keep the previous points in mind: since Aggra considers this a completion of the response, a thrown exception means you should have or should soon stop any work that you’re doing. - Only call dependencies with the device – if you call any node through another mechanism, there are to problems. First, if you call a non-dependency node, that means you’re not properly modeling the graph. Users will not know that the dependency exists and so may reason incorrectly about how the graph works. Second, if you undermine Aggra and obtain access to the node call’s current memory… and then if you use that to call another node, you can end up with a circular call, where the response from a node waits for itself to complete before completing. This will, obviously, never happen and cause progress in the graph call to stop. Aggra protects against this possibility as much as reasonably possible, but there are some points where you just have to read and follow the javadoc (e.g. give Aggra ownership of any created memory instance: don’t hold onto references to that memory and reuse it).
- Stop using the device at the end – the behavior must stop using the device until the latter of the following two events occurs: one, the call to the
runmethod returns a response, and two, the response completes. Aggra will weaklyClose the device at that point, which means it will do its best to fail any further usage, but this failure isn’t guaranteed. It’s ultimately your responsibility to make sure the behavior stops before that point. If you don’t, Aggra may not be able to track and properly handle any dependency calls you make.
Other Properties
Nodes have other properties, but those other properties are discussed in other parts of this wiki. Here’s just a quick recap:
- Role – a String-based description of what this node does (vs. Type, which describes the how it does it)
- Dependencies – nodes declare dependencies on other nodes. Those dependencies can either be primed or unprimed. Primed dependencies are pre-called during the node’s priming phase. Only once all primed nodes complete does the node then move on to the behavior phase.
- PrimingFailureStrategy – describes what to do if a primed dependency returns a failed response. The currently-available options are one, to continue waiting for the other primed dependencies to complete and then move on to the behavior phase or two, to stop the priming phase and move on directly to the waiting phase, using the primed dependency failure as the node’s response.
- DependencyLifetime – defines how long dependencies can run relative to this node. There are three option: one, NODE_FOR_ALL, where all direct and transitive dependencies must finish before this node is allowed to finish; two, NODE_FOR_DIRECT, where only direct dependencies must finish before this node may finish; or three, GRAPH, where all dependencies can finish whenever they want, up to the GraphCall level.
- Minimum DependencyLifetime – a node that has a dependency lifetime of GRAPH behaves like one that has NODE_FOR_ALL (and also NODE_FOR_DIRECT), since all dependencies will complete by the time the current node does (since no dependencies exist). Similarly, if a node has NODE_FOR_DIRECT, and all of its direct and transitive nodes do as well, then every node effectively has NODE_FOR_ALL as well. This concept is defined by “minimum dependency lifetime”, which is the minimum times that a node could be considered to have regardless of the lifetime it declares.
- CancelMode – describes the cancellation-related properties that the node has (e.g. which signals and hooks does it support). This property is determined, not explicitly by the user, but implicitly by the cancellation behavior they select. This will be discussed more in the section on cancellation below.
- ExceptionStrategy – defines how, when a node fails, that node responds to failures in dependencies. There current options are one, to dedupe and add those dependency failures as suppressed exceptions and two, to ignore the dependency failures completely.
- GraphValidatorFactories – describes how to create node-specific GraphValidators for the node during a GraphCall. These GraphValidators are run before a candidate graph is transformed into an official graph, allowing each node to define rules that its containing graph must conform to.
Cancellation
Cancellation is a pretty lengthy-topic, so it’s broken out into its own separate wiki.
Temporal orderings
Since Aggra is, at its heart, an asynchronous/concurrent framework, it’s important to define how its various steps relate to each other temporally. That is, which steps are guaranteed to happen before which other steps, and which steps may occur at any time relative to each other? (Note: This section is going to be mostly technical and potentially incomprehensible on first reading. This section is really getting down into the depths of Aggra here, probably most appropriate for Aggra developers.) (Note: any point marked <User Responsibility> indicates that it’s the user’s responsibility to establish this happens-before relationship.)
Helpful Background/Reminders
- A node call can
- Throw an exception before it returns a response
- Return a response that internally represents a failure/exception (e.g.
CompletableFuture#failedFuture) - Return a response that internally represents a success/non-exception (e.g.
CompletableFuture#completedFuture)
- Each node call has a dependency-calling device associated with it, to allow behaviors to call dependency nodes.
- For node’s supporting interrupt-based cancellation, each dependency-calling device has a lock associated with it. This lock allows for interrupt-modification in a way that doesn’t leak from a behavior to dependencies.
Node Call
The following are temporal orderings related to a node call:
- The call to Observer#observeBeforeEveryCall happens before the Memory’s storage is checked to see if a reply already exists for a node call.
- The call to Observer#observeBeforeEveryCall’s response’s ObserverAfterStop#observe method happens before the node call returns a response (or throws an exception)
- The call to Observer#observeBeforeFirstCall happens before the creation of a node call’s reply.
- The creation of a node call’s reply and storage in memory happens before the beginning of the priming phase.
- The first check of the GraphCall and MemoryScope cancellation signals happens before the beginning of the priming phase.
- The beginning of a node’s priming phase happens before any primed dependency is called
- The end of a node’s priming phase
- If any primed node throws an exception before returning a response when called during the priming phase, then that throwing of the exception happens before the end of the priming phase; otherwise
- If all primed nodes return a response, the based on the PrimingFailureStrategy
- WAIT_FOR_ALL_CONTINUE – with this value, the completion of all responses happens before the end of the priming phase completes.
- FAIL_FAST_STOP – with this value, the completion of the first primed dependency call response that internally represents a failure happens before the priming phase completes. If all primed dependency calls returns such a response that internally represents a success instead, then the rule for WAIT_FOR_ALL_CONTINUE applies.
- The second check of the GraphCall and MemoryScope cancellation signals happens before the end of the priming phase
- The end of the priming phase happens before the beginning of the behavior phase.
- The call to Observer#observeBeforeBehavior happens before the beginning of the behavior phase.
- The call to Observer#observeBeforeCustomCancelAction happens before the run of a behavior’s custom cancel action.
- The end of a behavior’s custom cancel action happens before the call to Observer#observeBeforeCustomCancelAction’s response’s ObserverAfterStop#observe method
- The call to Observer#observeBeforeCustomCancelAction’s response’s ObserverAfterStop#observe method happens before the end of the behavior phase.
- <User Responsibility> The final usage of a node call’s dependency-calling device happens before the latter of the following: the behavior returning a response (or throwing an exception) and the behavior response’s completion (which isn’t relevant in the case of a thrown exception).
- The behavior response’s completion happens before the call to Observer#observeBeforeBehavior’s response’s ObserverAfterStop#observe method (unless the behavior’s threw an exception, which then happens before the observe method is called).
- The call to Observer#observeBeforeBehavior’s response’s ObserverAfterStop#observe method happens before the end of the behavior phase.
- The end of the priming phase happens before the beginning of the waiting phase. This is important to call out, because not every node call has a behavior phase.
- The end of the behavior phase happens before the beginning of the waiting phase.
- The end of the waiting phase depends on the value of the node’s dependency lifetime
- NODE_FOR_ALL – the completion of all direct dependency calls made during the node call (that returned a response) happens before the end of the waiting phase. In addition, the completion of all transitive dependency calls made by those direct dependency calls (regardless of when they were made) happens before the end of the waiting phase.
- NODE_FOR_DIRECT – the completion of all direct dependency calls made during the node call (that returned a response) happens before the end of the waiting phase.
- GRAPH – there is nothing extra to add here.
- The end of the waiting phase happens before the call to Observer#observeBeforeFirstCall’s response’s ObserverAfterStop#observe method.
- The call to Observer#observeBeforeFirstCall’s response’s ObserverAfterStop#observe method happens before the completion of the node call’s reply.
There are additional temporal orderings for nodes whose behaviors support interrupt-based cancellation.
- For dependency calls
- The locking of a dependency-calling device’s interrupt lock happens before the current thread’s interrupt status is saved and then cleared using the user-provided InterruptModifier.
- The current thread’s interrupt status’s saving and clearing happens before any dependency call.
- The end of a dependency call (e.g. the return from DependencyCallingDevice#call) happens before the thread’s saved interrupt status is restored to its previous value.
- The thread’s interrupt status’s restoration happen before the unlocking of the dependency-calling device’s interrupt lock.
- The unlocking of the dependency-calling device’s interrupt-lock happens before control is restored to the node’s behavior
- For runs of the custom cancel action
- The locking of a dependency-calling device’s interrupt lock happens before the current thread’s interrupt status is saved and then cleared using the user-provided InterruptModifier.
- The current thread’s interrupt status’s saving and clearing happens before the user-provided custom cancel action is run.
- The end of the custom cancel action happens before the thread’s saved interrupt status is restored to its previous value.
- The thread’s interrupt status’s restoration happen before the unlocking of the dependency-calling device’s interrupt lock.
- The unlocking of the dependency-calling device’s interrupt-lock happens before control is restored to the caller of the custom cancel action (this caller is internal to the Aggra framework)
- At the end of a node call
- The beginning of the waiting phase happens before the current thread’s interrupt status is cleared using the user-provided InterruptModifier.
- The current thread’s clearing happens before control is returned to the initiator of the waiting phase
Graph Call
The following are temporal orderings related to a graph call:
- <User Responsibility> The final call to GraphCall#call happens before the call to GraphCall#weaklyClose.
- The completion of all responses from all calls to GraphCall#call happens before Aggra automatically triggers the GraphCall cancellation signal as a part of the response from weaklyClose. (If the call to GraphCall#call throws an exception, the call does not factor into this point.)
- All of the following happens before the response from weaklyClose completes
- Aggra automatically triggers the GraphCall cancellation signal (which is allowed to trigger MemoryScope and Reply cancellation signals as well, if appropriate)
- The completion of the responses from all node calls made as a part of the GraphCall
Miscellaneous
The following are various temporal orderings related to Aggra:
- The completion of the responses from all externally-accessible nodes of a MemoryScope happens before Aggra automatically triggers the MemoryScope’s MemoryScope cancellation signal (which is allowed to trigger child MemoryScope and Reply cancellation signals as well, if appropriate). “Externally accessible” means that a consumer (which may be a caller outside of the GraphCall or a node from inside of it) is able to call the node.
- <User Responsibility> All major work for a behavior happens before a behavior completes its returned response (or throws an exception before returning a response). This is an informal temporal ordering which is important to mention, because it helps ensure that the resources a GraphCall uses are returned as closely as possible to the end of the GraphCall.